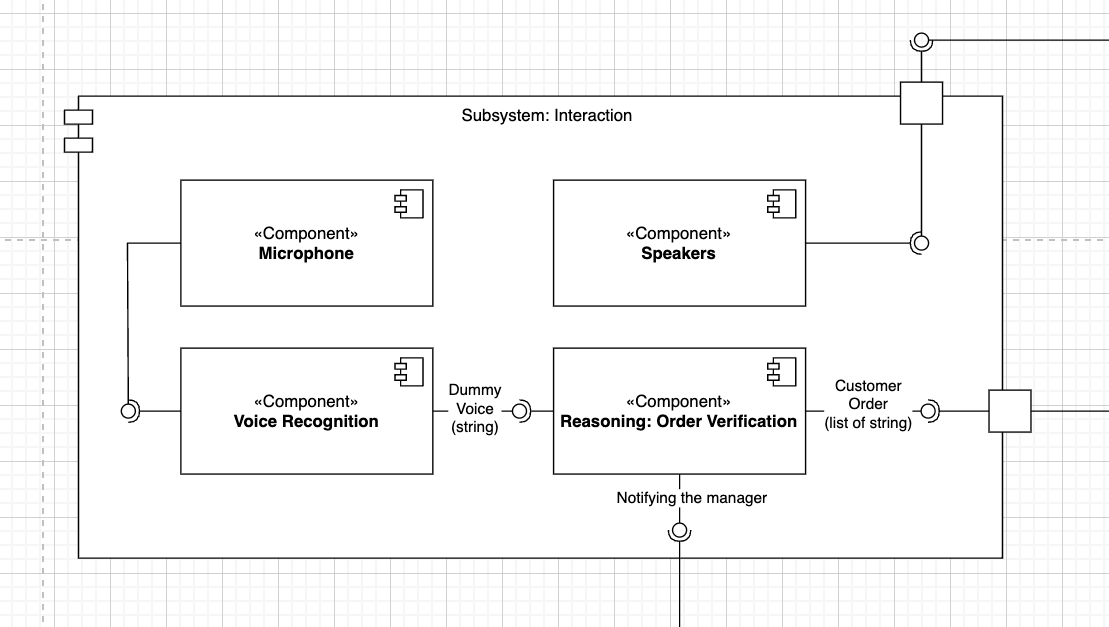
Subsystem Interaction
What the Interaction subsystem does
The Interaction layer is responsible for all spoken I/O between customers and the TIAGo fleet:
Capture raw audio events (or simulate them) from microphones.
Recognise spoken commands, converting integer “utterances” into plain‐text.
Validate customer orders (“Can I have …”) before they enter the task queue, catching missing requests or unknown dishes.
Announce robot status and customer notifications in a human‐friendly, rate‐controlled fashion.
Design Patterns
Observer
voice_recognition.py and speaker.py both subscribe to topics (mic_channel or speaker_channel) and process each incoming message as soon as it arrives. This push‐based design eliminates polling and guarantees each event is handled exactly once, keeping latency low and resource usage efficient.
Adapter
voice_recognition.py implements a dictionary‐based adapter that maps raw Int32 codes into natural‐language sentences. By centralising this mapping, the downstream order verification node never sees numeric keys—only human‐readable text—keeping the ASR stub and the verification logic cleanly separated.
Strategy
reasoning_order_verification.py uses a simple substring‐match strategy to detect the “Can I have” fragment and a list‐matching strategy for dish recognition. In the future we could swap in a more sophisticated NLP strategy (e.g. regex‐based, ML‐based entity extraction) without changing the orchestration of parse → validate → publish.
Template Method
speech_generator.py implements a fixed two‐step loop—cache incoming text, then publish it at 1 Hz—while allowing customization of caching or republishing hooks. To introduce context‐aware gating or dynamic rate adaptation, we override only those hook methods, not the entire republishing flow.
Command
reasoning_order_verification.py wraps validated orders in a tiago1/Voice_rec message and also constructs a send_orderRequest for the /robot_state_decision_add service. Both the publish and service‐call act like commands that can be retried, queued or extended, decoupling the verification logic from the rest of the orchestration.
Chain of Responsibility
In reasoning_order_verification.py, the parse_order() method applies a sequence of checks—polite‐request guard, dish‐matching guard, then structured message creation or error emission. We can insert additional validation steps (e.g. profanity filter, multi‐language support) simply by adding new handlers to this chain without rewriting existing logic.
Component roles
microphone.py - Publishes a random or real std_msgs/Int32 on /<robot>/mic_channel to emulate microphone events at 1 Hz.
voice_recognition.py - Subscribes to /mic_channel, maps each Int32 key → sentence via a lookup dict, and publishes std_msgs/String on /voice_recogn.
reasoning_order_verification.py - Listens to /voice_recogn, checks for the fragment “Can I have” and valid dishes from a food_list. - On success, publishes a structured tiago1/Voice_rec to /verif_T_manager and calls the send_order service; on failure, emits error codes (1 = no dish, 2 = missing phrase) on /error_from_interaction.
speech_generator.py - Buffers the latest text command from /task_speech_command and republishes it at 1 Hz on /speaker_channel, ensuring no more than one announcement per second.
speaker.py - Subscribes to /speaker_channel and immediately relays each std_msgs/String to /speaker_output, with latching so late‐joining TTS drivers still hear the last message.
ROS interfaces & KPIs
Topic / Service |
Type |
KPI / Note |
|---|---|---|
|
|
1 Hz, latency ≤ 100 ms |
|
|
Word error rate ≤ 5 % on test set |
|
|
Code 1 (no dish) < 2 % of valid orders |
|
|
Published ≤ 200 ms after utterance |
|
|
One buffer slot, no drops |
|
|
Latched; late TTS subscribers still get last sentence |
Implementation modules
Click any component for full API documentation.
Interaction Components